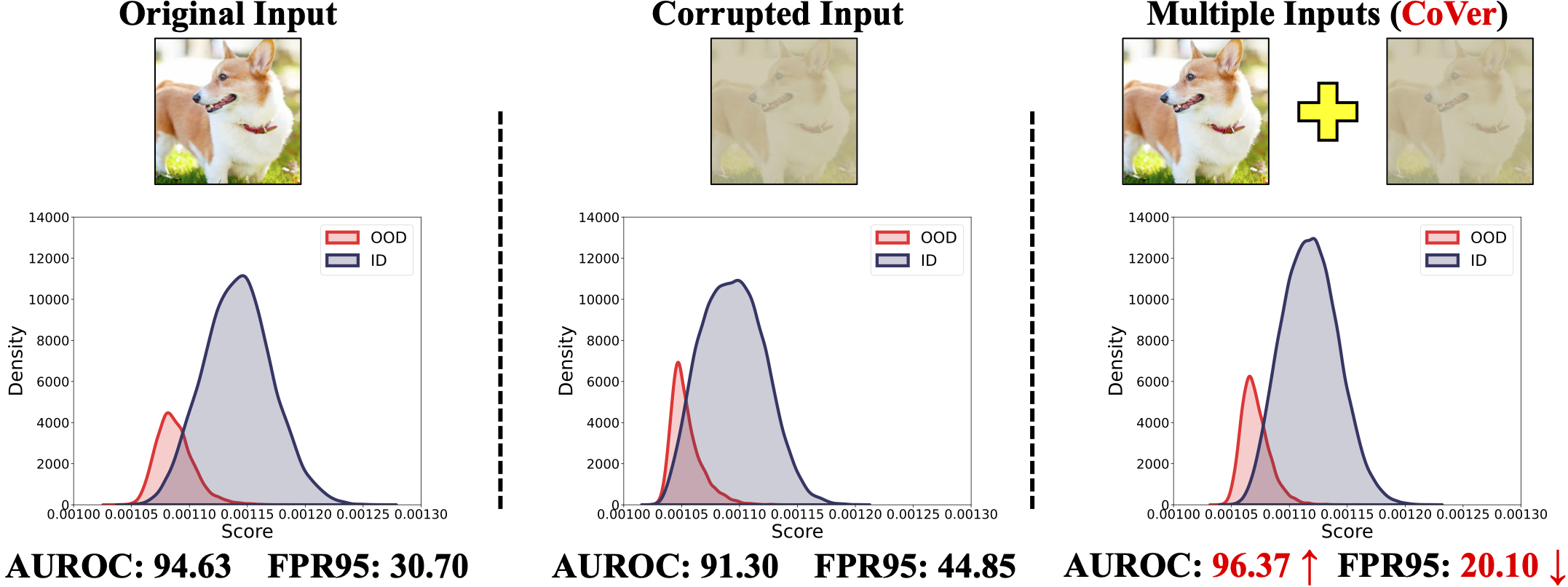
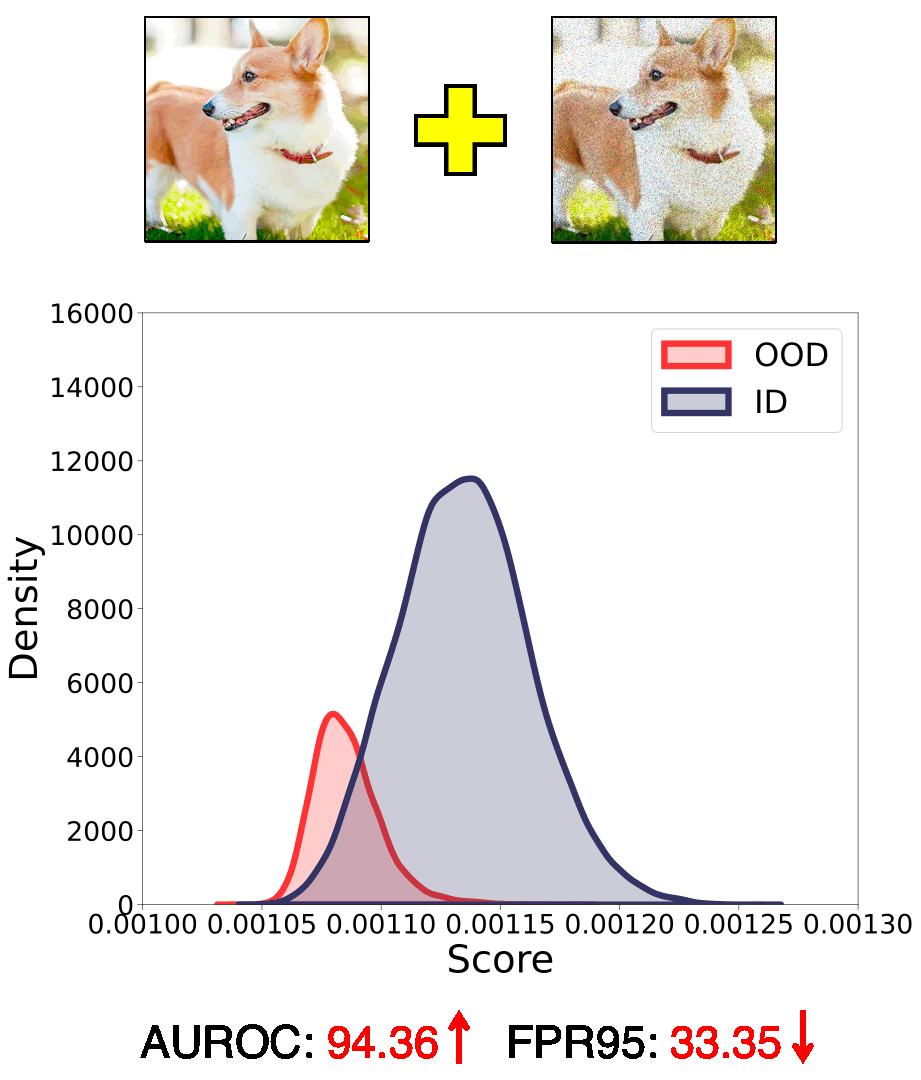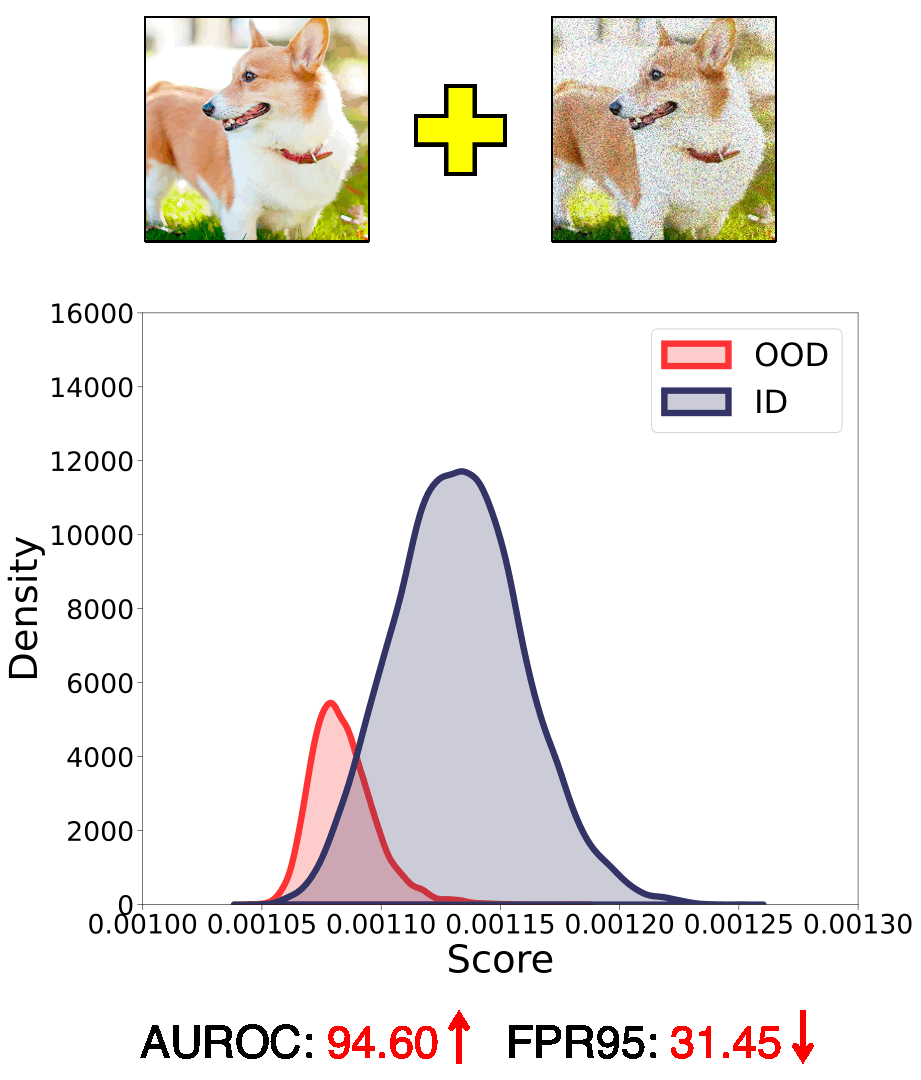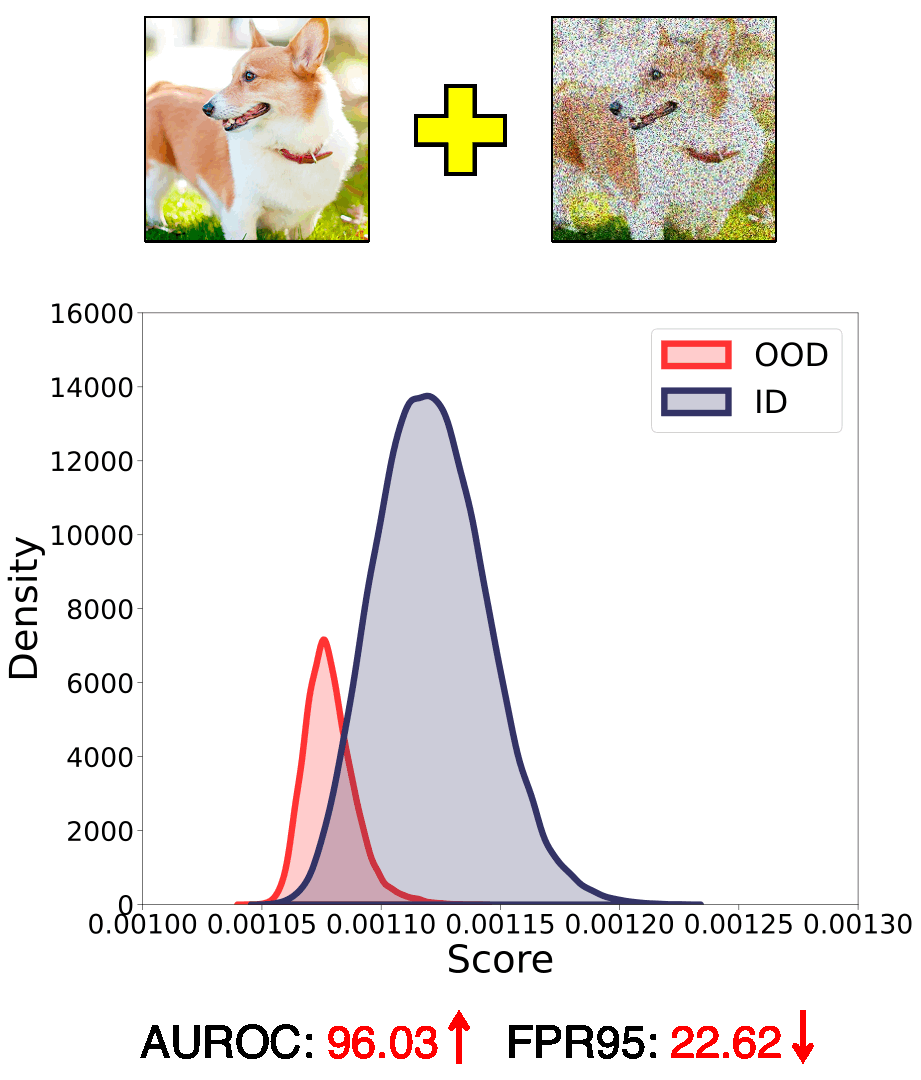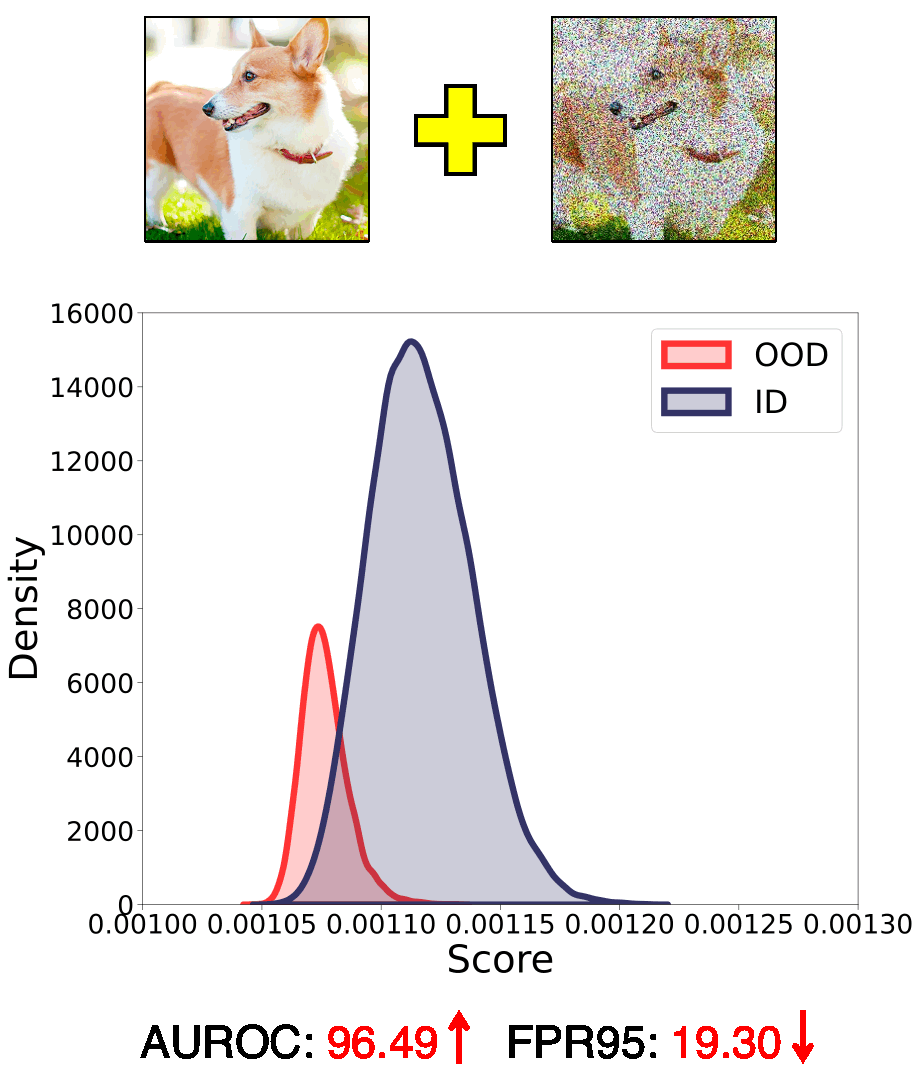
Out-of-distribution (OOD) detection aims to identify OOD inputs from unknown classes, which is important for the reliable deployment of machine learning models in the open world. Various scoring functions are proposed to distinguish it from in-distribution (ID) data. However, existing methods generally focus on excavating the discriminative information from a single input, which implicitly limits its representation dimension.
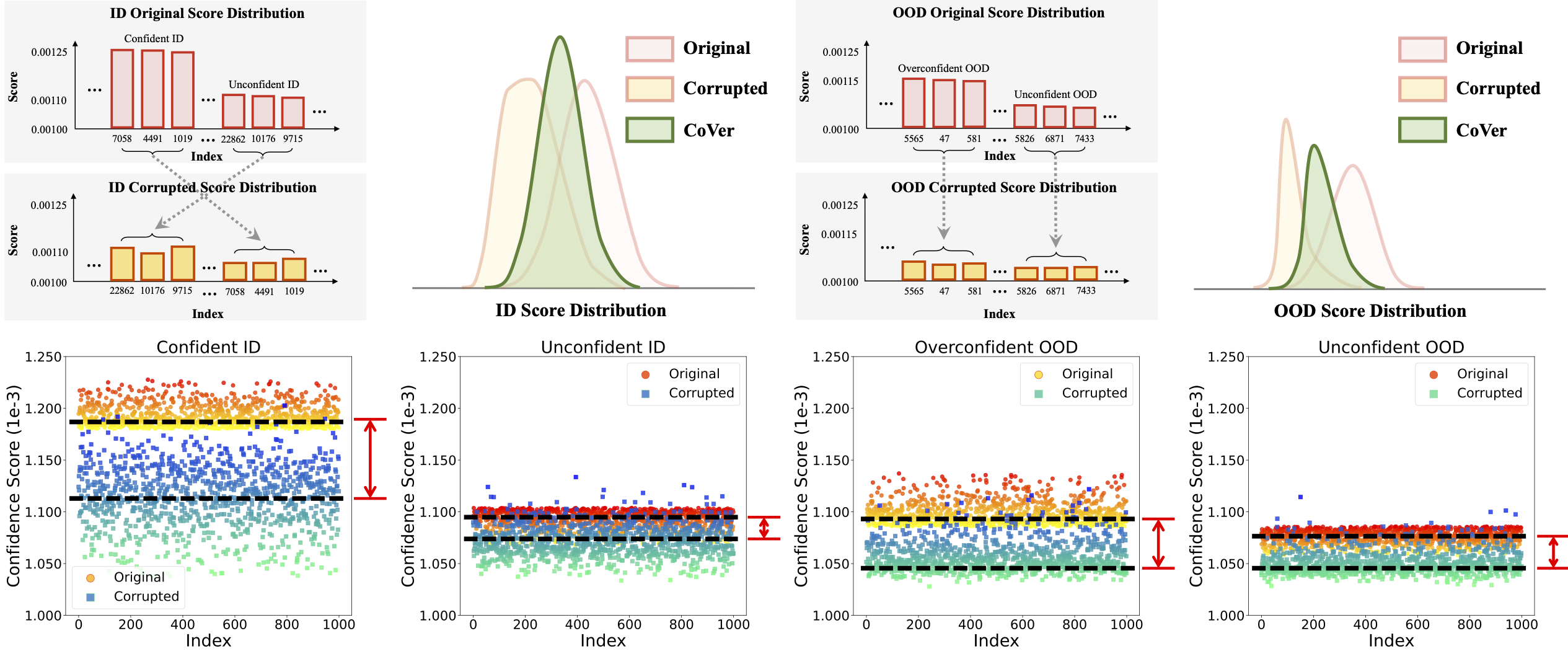
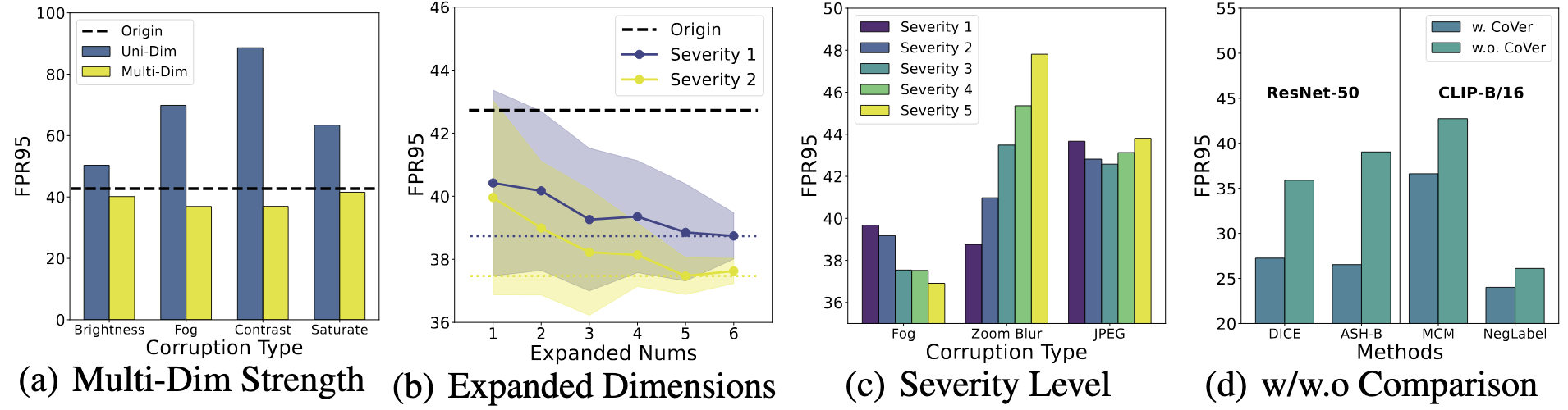
In this work, we introduce a novel perspective, i.e., employing different common corruptions on the input space, to expand that. We reveal an interesting phenomenon termed confidence mutation, where the confidence of OOD data can decrease significantly under the corruptions, while the ID data shows a higher confidence expectation considering the resistance of semantic features.
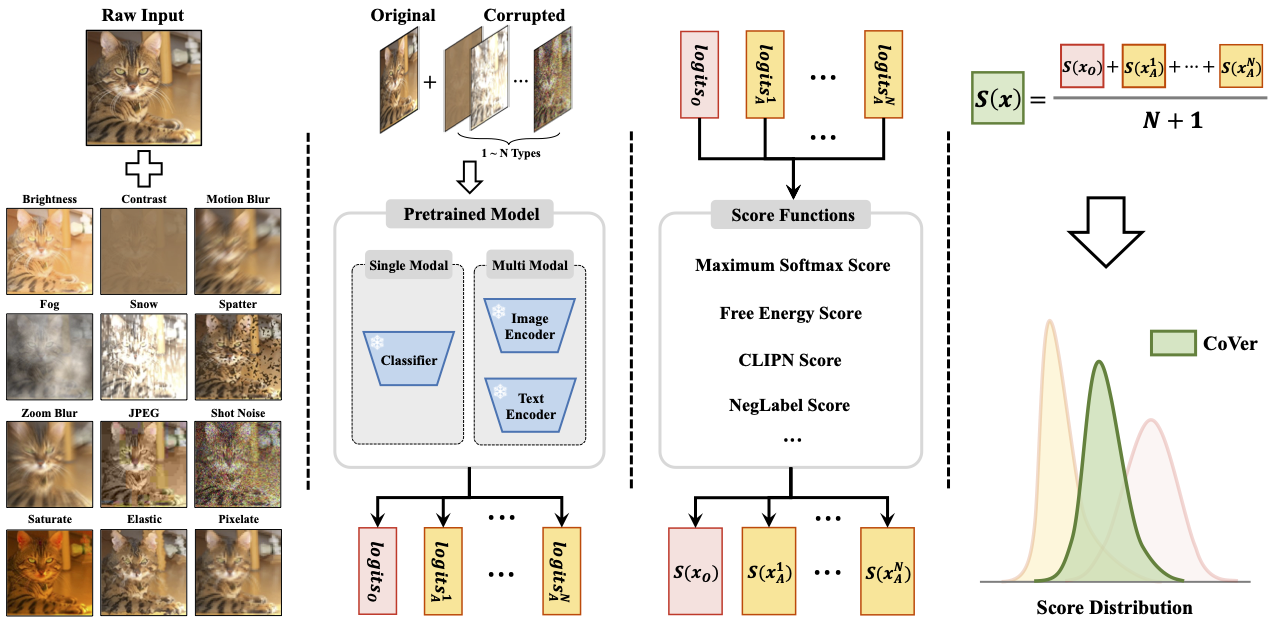
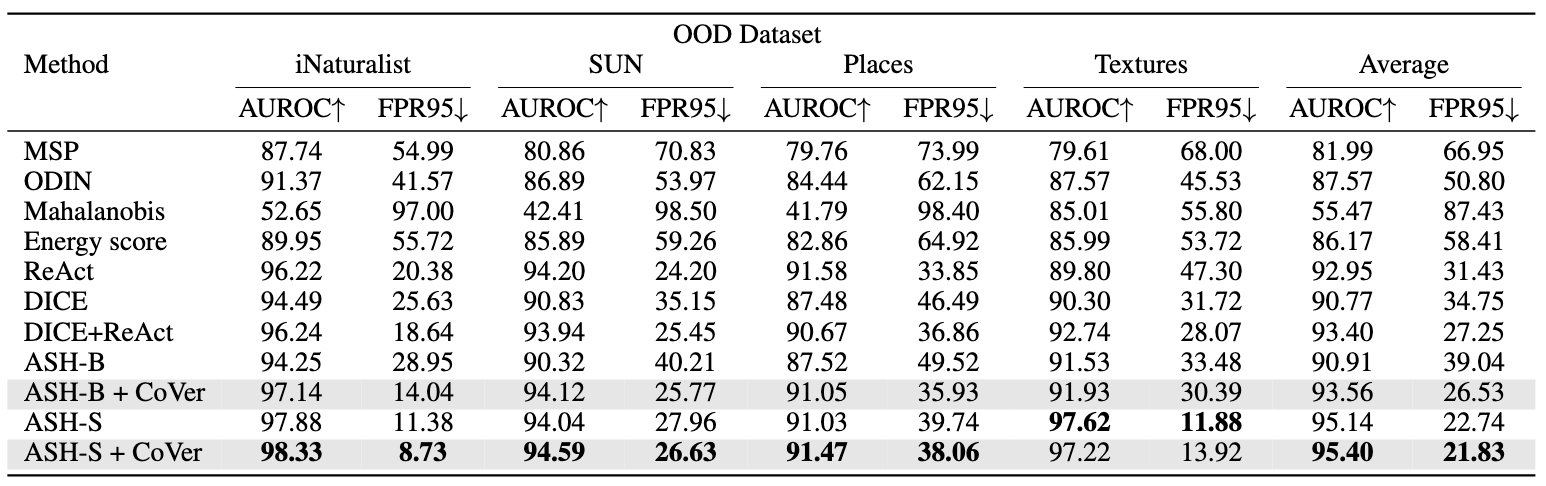
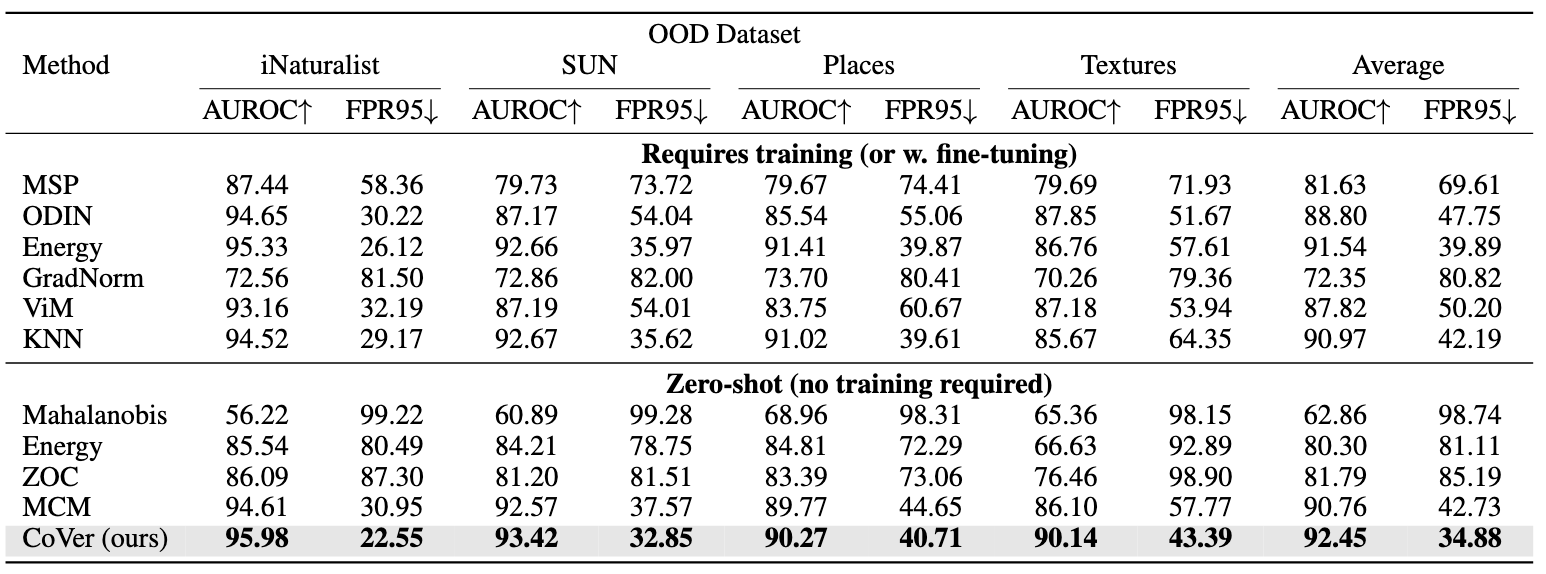
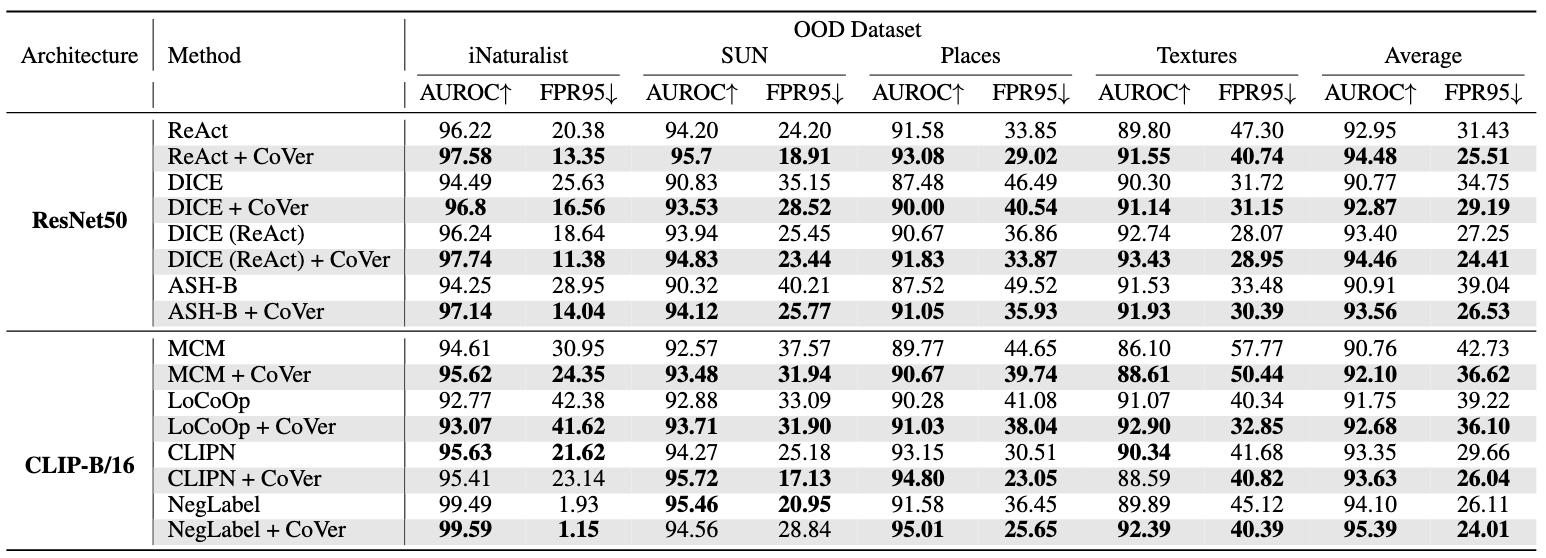
Based on that, we formalize a new scoring method, namely, Confidence aVerage (CoVer), which can capture the dynamic differences by simply averaging the scores obtained from different corrupted inputs and the original ones, making the OOD and ID distributions more separable in detection tasks. Extensive experiments and analyses have been conducted to understand and verify the effectiveness of CoVer.
We are releasing two calls alongside this paper to encourage, increase, and broaden the reach of scientific interactions and collaborations. The two calls are an invitation for fellow researchers to address two questions that are not yet sufficiently answered by this work:
For each call we provide possible directions to explore the answer, however, we encourage novel quests beyond what's suggested below.
Call for explanation and theoretical understanding. In our paper, we provide a possible explanation of the effectiveness of CoVer from the empirical perspective. We suggest that common corruptions might act as perturbations of high-frequency features within the input representation. For OOD samples, which inherently lack ID semantic features, altering high-frequency features could potentially lead to notable changes in model confidence, while the ID data shows relatively better resistance on it. However, there lacks of rigorous theoretical understandings on this empirical observation.
Call for validation in other fields. We believe any domains that use a deep neural network (or a similar intelligent system) to learn representations of data when optimizing for a training task could be a fertile ground for validating CoVer. A clear domain is natural language processing, where both original and corrupted inputs, similar to CoVer, could be applied to language models like LLMs. Can the combination of original and corrupted inputs effectively enhance the OOD detection capability in language models like LLMs? Another possible domain for validation could be time-series models, where temporal disruptions in the input space could simulate perturbations analogous to our proposed method. Would such input variations help to enhance OOD detection in time-series predictions? We invite exploration of CoVer's potential in these and other fields to assess whether utilizing both original and corrupted inputs can provide new perspectives for improving model performance and robustness.
We are still working to set up a proper portal for submitting, reviewing and discussing answers to both calls. In the meantime, feel free to email zhangboxuan1005@gmail.com to start a conversation.
@inproceedings{zhang2024what,
title = {What If the Input is Expanded in OOD Detection?},
author = {Zhang, Boxuan and Zhu, Jianing and Wang, Zengmao and Liu, Tongliang and Du, Bo and Han, Bo},
booktitle = {The Thirty-Eighth Annual Conference on Neural Information Processing Systems},
year = {2024},
}